I was chatting to people at a search conference recently and we got onto the subject of language and how it changes according to context. Language is a common topic at these events – after all, our job as search experts is often to deal with the intricacies of linguistics and search itself can be considered as a translation problem, from whatever the user says or types to the way you describe your data. One of the group talked about the many ways to ask for a cup of coffee in different languages or situations.
Effective search applications (and by extension, AI systems like RAG) are also hugely dependent on context. What you type as a search query is really only one datapoint we can use when deciding what results to give you – who you are, where you are, what you’ve done in the past, what others like you have done and indeed what we’re offering are also important.
Different types of context
Let’s take popularity as one example, as it’s a common way to influence how search results are ranked. In a simple search scenario, our user searches for ‘science fiction film’ and we push Dune 2 higher up the list, as many people have already downloaded and watched this epic. Popularity in this case is a very simple scalar number, based on what others have done: it’s popularity in a global context (at least, global within our user base).

However, the user may not have liked Dune 1 and have an aversion to sand or worms, and may thus have rated Dune 1 with only one star out of 5. In their own local context, perhaps Dune 2 shouldn’t be ranked as highly.

Another context might be availability. For a simple web store, a product may be available or not, a binary value, but for a large supermarket chain with many physical stores, some central shipping facility and constantly changing stock levels at all of these, this context is more complicated: it depends on whether you’re happy as a user with central shipping, or to pick the item up next time you’re in a store (which should be local to your home or office – unless perhaps you’re on holiday). Availability is a context both global (is the item available at all) and local – (is it easily and conveniently available to the user).
The context of how the query itself is written is also important to consider. Every user has a slightly different view of the world and will express themselves accordingly. The queries ‘New film with Zendaya on desert planet’ and ‘Dune 2’ are asking for the same result – and that’s before you bring in different languages, some of which may not be native to the user. Today, we’re also dealing with spoken search queries or even queries by image (‘what butterfly is this a picture of?’). To deal with this multi-modal world we turn to vector search – but the model we use to turn a query into a vector itself provides another level of context depending on how it has been trained. A generic embedding model, un-tuned on your type of data, may not produce high quality results – it simply isn’t aware of the context it needs to operate in. Fine-tuning is a common solution.
In AI applications, lack of sufficient context can be an even bigger problem – we’ve all seen examples of LLMs creatively interpolating between the data they have been trained on, or more simply – making stuff up. RAG systems aren’t immune from this either if the search system that provides the ‘R’ part doesn’t have the full context.
Using context in search
All of these different contexts affect both the matching and ranking stages of presenting search results. Ranking itself is now often multi-stage, partly to address the issue that the more complex the ranking processing required the higher the cost – so we first try a cheap method on all the results, to cut down the set of possible results for subsequent, more expensive stages.
The examples from the literature are usually simplistic: perform a keyword search, then use a scalar number representing popularity to influence the ranking of the results. It’s rare to find examples of how to do this with more complex – and possibly multidimensional – contextual data. Quite often the search engine itself doesn’t have the capability to do this, so we rely on external systems to pre-process and reduce this data to something the search engine can work with. Although vector indexing is now a standard feature of most search platforms, it’s still not obvious how best to combine this with keyword search, although there are some encouraging ideas (Bayesian BM25 being one).
If we are to make it easier to use this complex, multidimensional contextual data in our search & AI applications then these platforms will need to evolve. We can see that some now have the ability to create multistage ranking pipelines and to host ML models directly within their infrastructure – although this usually doesn’t cover all possible models as it can be constrained by the search platform’s architecture. The question is, even with these capabilities, can data be stored and manipulated in the right way.
New ways to represent context
Future search platforms will need to be able to store and manipulate contextual multidimensional data as a matter of course, with this data being available for both matching and ranking stages. We can’t keep bolting features and data structures onto existing, restrictive architectures – this leads to limited capabilities and scaling issues.
I don’t see many of the search platforms available today addressing this issue – with the exception of Vespa, which has the advantage of having been built for massive scale from the beginning, when built at Yahoo. Vespa includes tensor mathematics as a first class citizen, with highly optimised and performant tensor manipulations being possible within the engine and available for matching and ranking. Simply put, doing everything in one place is a huge advantage. I’m looking forward to learning more about tensors at the first Vespa conference I’m co-organising in London this September (tickets are now available).
Tensors can be considered as a generalisation of scalars, vectors and higher dimension mathematical constructs. With this capability it’s possible to use all the aforementioned contextual information directly within the search platform, without having to do the heavy lifting in external systems, or reduce and possibly oversimplify representations of context. For both traditional search and agentic AI workloads this reduces overall architectural complexity and can increase overall performance.
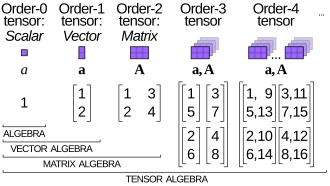
Tensors are not yet well understood within the search community, although they will be more familiar to machine learning experts. Over the last few years, vector search has become a standard part of most search platforms (conversely, vector databases have often had to retrofit traditional search capabilities as these are still useful in many situations). Tensors are the next thing we will have to work with if we are to continue to build performant and accurate search and AI applications.
Context is important – and we need to be able to use it properly!
Big Data Technology Vectors by Vecteezy
3d Stock photos by Vecteezy
Out Of Stock Vectors by Vecteezy
Tensor diagram by Wikipedia contributor Cmglee – Creative Commons CC BY-SA 4.0